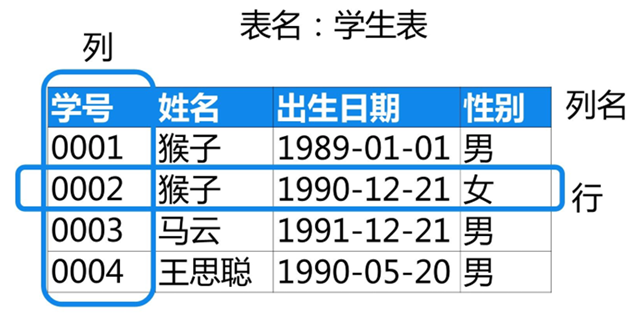
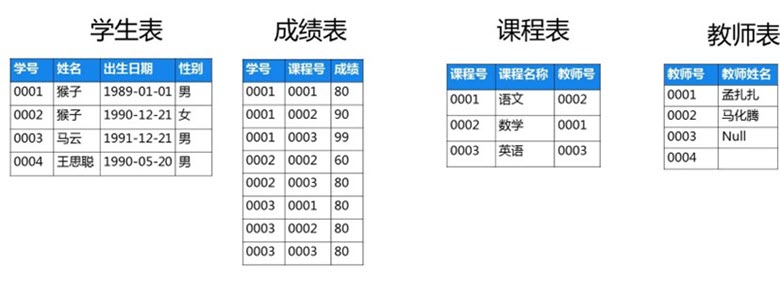
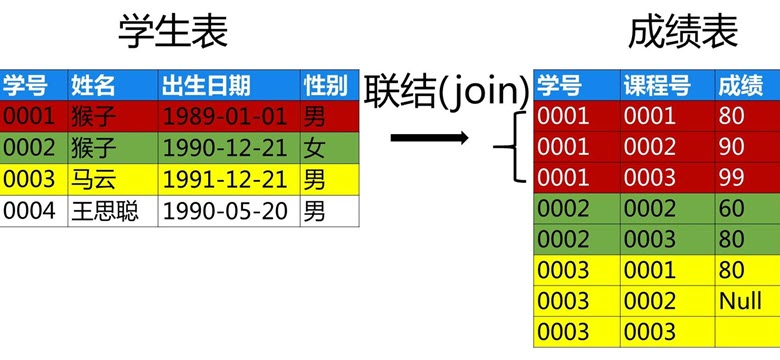
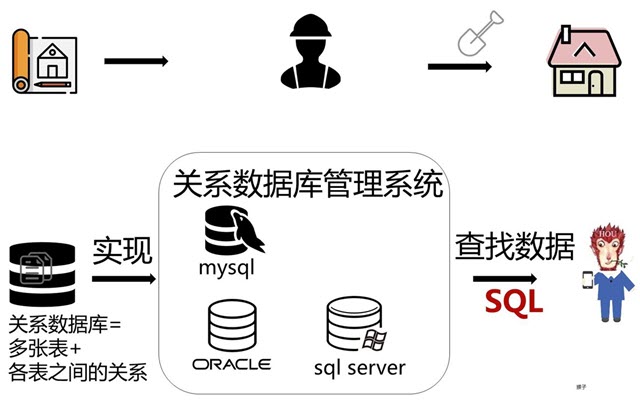
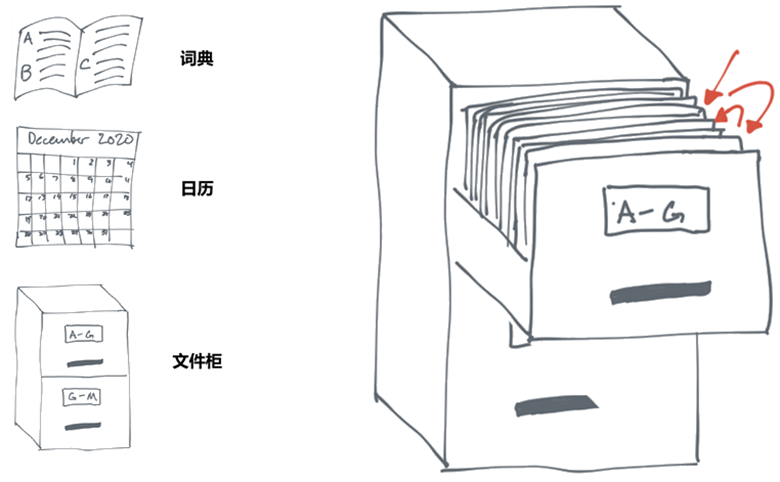
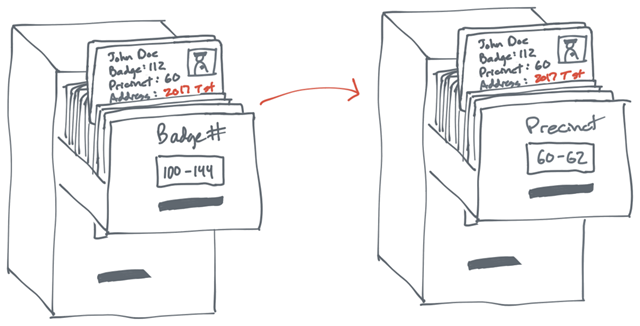
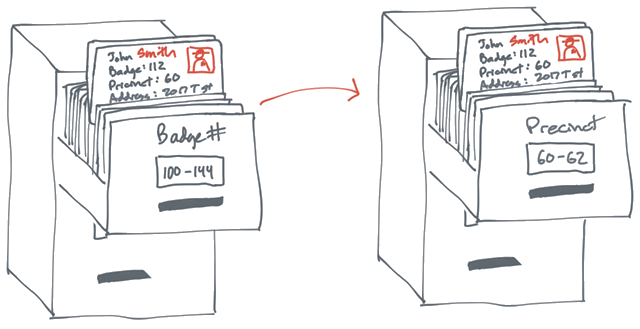
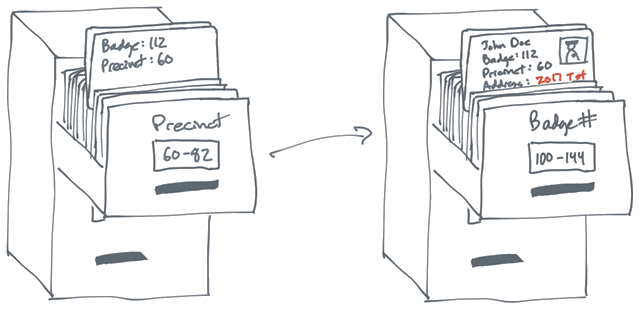
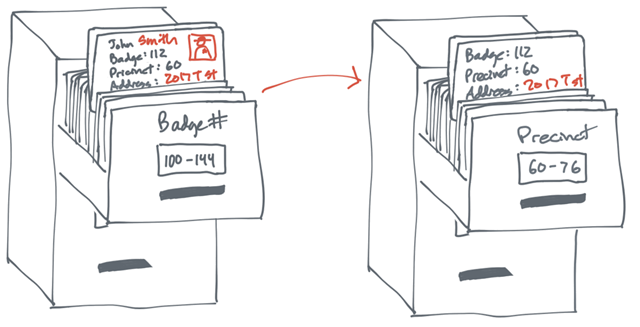
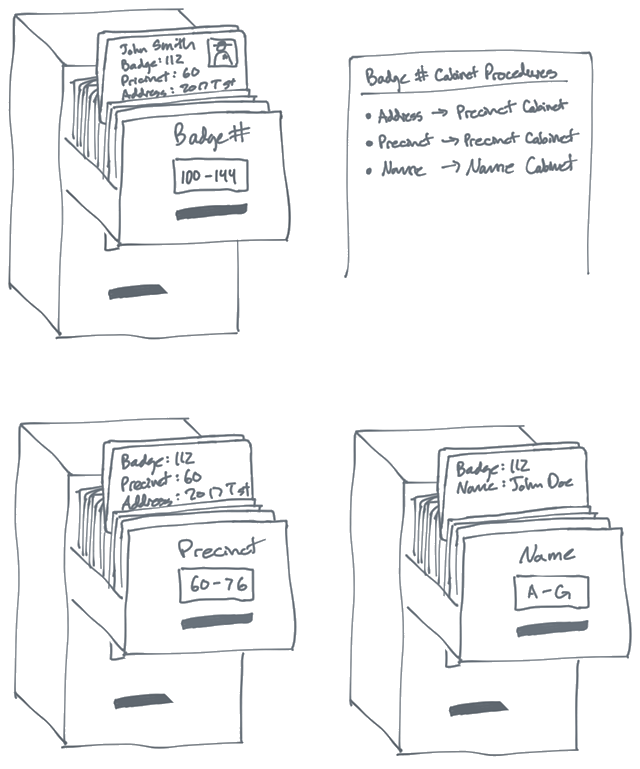
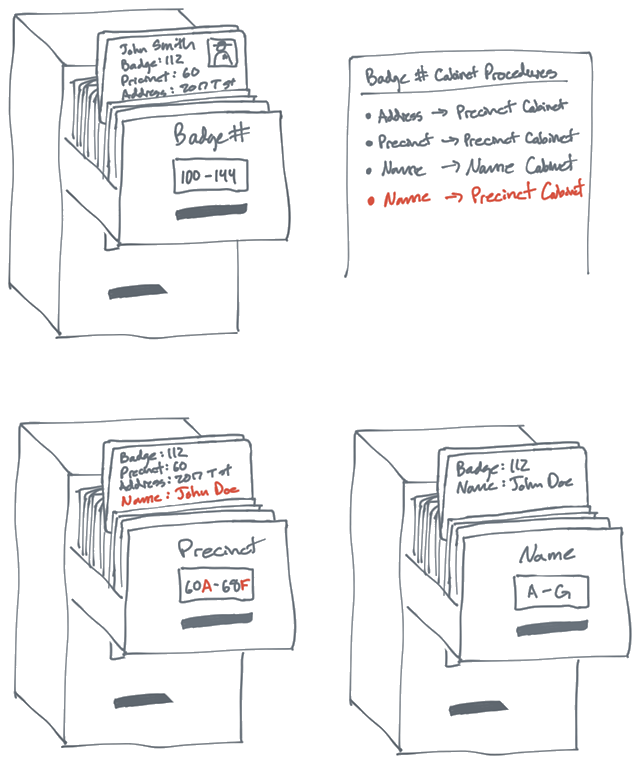
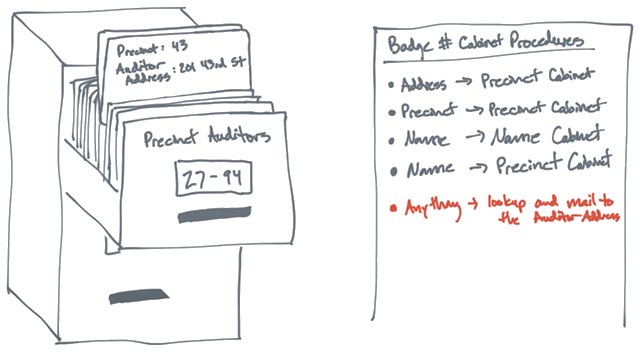
APP唤醒与场景还原
在App投放推广中,唤醒用户是常见的运营策略。想要让用户重新活跃起来,转化用户的行为,必须从场景上还原用户的路径,从根本上找到用户增长的奥秘。
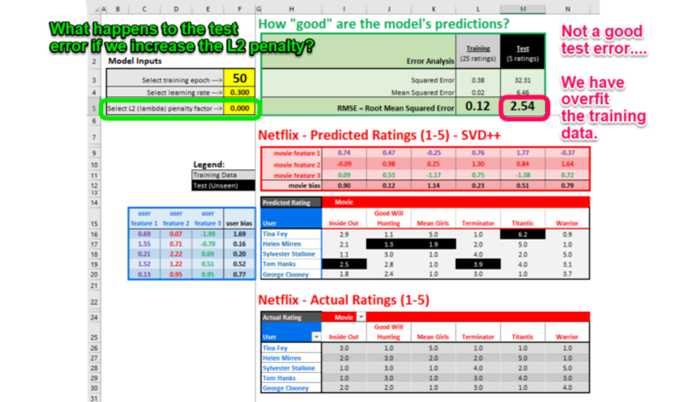
在这个广告漫天的时代,相信大多数用户在使用App的时候都遇到类似的场景:在使用某资讯类App的时候,浏览到了淘宝的商品广告,当你点击该广告内容时,自动打开了你手机上已经安装的淘宝App并且定位到了该商品的详情页。
- 作为用户,心里一定在想:“这购物真方便,都不要自己打开淘宝搜索商品了”。
- 作为广告主,心里在想:“又拉活了一个用户,说不定还能带来一笔转化”。
那么,资讯类App是如何唤醒淘宝App的呢,淘宝App又是如何跳转至用户浏览的广告页面呢?
唤醒&场景还原,作为运营常用的拉活增长手段,有利于提升老用户在App的活跃度,场景化的唤醒更能激发用户的转化意愿。
其适用于如下几个营销场景:
- 浏览器 -> 唤醒APP:用户A在手机上通过浏览器打开了某APP的M站或者官网,则引导用户打开该APP或者下载该APP。
- 微信、QQ等 -> 唤醒APP:用户通过某APP分享了一条链接至微信或QQ,用户B点开该链接后,引导用户B打开该APP或者下载该APP。
- 短信、邮件、二维码等-> 唤醒APP:用户A打开了某APP的推广短信,邮件或者扫描二维码等,引导用户打开该APP或者下载该APP。
- 其他APP -> 唤醒APP:用户A通过第三方APP分享了一条链接至用户B,用户B点开该链接后,引导用户B打开指定APP或者下载指定APP。
![]()
常见唤醒APP方式
URL Scheme
URI Schema 是这几种调起方式中最原始的一种,只需要原生APP开发时注册scheme, 那么用户点击到此类链接时,会自动唤醒APP,借助于URL Router机制,则还可以跳转至指定页面。这种方式是当前使用最广泛,也是最简单的,但是需要手机APP支持URL Scheme。
iOS URL Scheme
iOS的沙盒机制
iOS选择沙盒来保障用户的隐私和安全,但沙盒也阻碍了应用间合理的信息共享,于是有了 URL Schemes 这个解决办法。一般来说,我们使用的智能设备上有许多我们的个人信息。比如:联系方式、银行卡/信用卡信息、支付宝/Paypal/各大商城的账户密码、照片甚至行程与位置信息等。
如果说,你设备上的每一个应用,不管是官方的还是你从任何商城安装的应用都可以随意地获取这些信息,那么你轻则收到骚扰信息和邮件、重则后果不堪设想。如何让这些信息不被其它应用随意使用,或者说,如何让这些信息仅在设备所有者本人知情并允许的情况下被使用,是所有智能设备与操作系统所要在乎的核心安全问题。
在 iOS 这个操作系统中,针对这个问题,苹果使用了名为「沙盒」的机制:应用只能访问它声明可能访问的资源。一切提交到 App Store 的应用都必须遵守这个机制。
在安全方面沙盒是个很好的解决办法,但是有些矫枉过正。敏感的个人信息我们不愿意透露,却不代表所有的信息我们都不想与其它应用共享。比如说我们要一次性地(没错,只按一次)把多个事件放到日历中,这些事件包含日期时间以及持续时间等信息,如果 App 之间信息不能沟通,就无法做到这点。类似于一次性添加多个日历事件这样的,我们在使用智能设备的过程中会遇到很多不必要的重复的步骤。大多数人对这些重复的步骤是不自觉的,就像当自己电脑里有一批文件需要批量重命名的时候,他们机械地重复着重命名的过程。但是当我们掌握了这些设备运行的模式,或者有了一些工具,我们就能将这些重复的步骤全部节省下来。在 iOS 上,我们可以利用的工具就是 URL Schemes。
URL Schemes 是什么
通过对比网页链接来理解 iOS 上的 URL Schemes,应该就容易多了。
URL Schemes 有两个单词:
- URL,我们都很清楚,http://www.apple.com 就是个 URL,我们也叫它链接或网址;
- Schemes,表示的是一个 URL 中的一个位置——最初始的位置,即 ://之前的那段字符。比如 http://www.apple.com 这个网址的 Schemes 是 http。
根据我们上面对 URL Schemes 的使用,我们可以很轻易地理解,在以本地应用为主的 iOS 上,我们可以像定位一个网页一样,用一种特殊的 URL 来定位一个应用甚至应用里某个具体的功能。而定位这个应用的,就应该这个应用的 URL 的 Schemes 部分,也就是开头儿那部分。比如短信,就是 sms:
你可以完全按照理解一个网页的 URL ——也就是它的网址——的方式来理解一个 iOS 应用的 URL,拿苹果的网站和 iOS 上的微信来做个简单对比:
| 网页(苹果) | iOS 应用(微信) |
| 网站首页/打开应用 | http://www.apple.com | weixin:// |
| 子页面/具体功能 | http://www.apple.com/mac/ | weixin://dl/moments |
在这里,http://www.apple.com 和 weixin:// 都声明了这是谁的地盘。然后在 http://www.apple.com 后面加上 /mac 就跳转到从属于 http://www.apple.com 的一个网页(Mac 页)上;同样,在 weixin:// 后面加上 dl/moments 就进入了微信的一个具体的功能——朋友圈。
但是,两者还有几个重要的区别:
- 所有网页都一定有网址,不管是首页还是子页。但未必所有的应用都有自己的 URL Schemes,更不是每个应用的每个功能都有相应的 URL Schemes。实际上,现状是,大多数的应用只有用于打开应用的 URL Schemes,而有一些应用甚至没有用于打开应用的 URL Schemes。几乎没有所有功能都有对应 URL 的应用。所以,不要说某某应用烂,不支持国内应用。一个 App 是否支持 URL Schemes 要看那个 App 的作者是否在自己的作品里添加了 URL Schemes 相关的代码。
- 一个网址只对应一个网页,但并非每个 URL Schemes 都只对应一款应用。这点是因为苹果没有对 URL Schemes 有不允许重复的硬性要求,所以曾经出现过有 App 使用支付宝的 URL Schemes 拦截支付帐号和密码的事件。
- 一般网页的 URL 比较好预测,而 iOS 上的 URL Schemes 因为没有统一标准,所以非常难猜,通过猜来获取 iOS 应用的 URL Schemes 是不现实的。
基本 URL Schemes
基本 URL Schemes 的能力虽然简单有限,但使用情境却是最普遍的。所谓的基本 URL Schemes,是指一个 URL 的 Schemes 部分,比如上文提到的微信的 weixin:。这个部分的唯一功能,就是打开相应应用,而不能够跳转到任何功能。
绝大多数所谓支持 URL Schemes 的应用,一般都是只有这么一个部分,它一般是这个应用的名称,比如 OmniFocus 这款应用,它的基本 URL Schemes 就是 Omnifocus:。如果应用的主名称是个中文名的话,它的 URL Schemes 也许会是应用名的拼音,比如 墨客 这款应用,它的基本 URL Schemes 是 moke:。但网页 URL 和 iOS 应用的 URL 的三个重要区别,其中第三项,就是 iOS 上的 URL Schemes 并不规范,一个应用的 URL 可以是各种各样的:
- Coursera 的 URL 是:coursera-mobile:
- Duet 这款游戏的 URL 是:x-kumo-duet:
- Monument 这款游戏的 URL 是:fb690517270143345:
- Feedly 的 URL 是:fb129765800430121:
- 扇贝新闻的 URL 是:wx95962d02b9c3e2f7:
它们目前并没有统一的规则,所以猜测一个应用的意义并不太大,你可以试试,但不要过于指望这种方式。下文会提到如何查找一个应用的基本 URL Schemes,只要那个应用支持 URL Schemes 就能找到。基本 URL Schemes 的能力虽然简单有限,但使用情境却是最普遍的。
复杂 URL Schemes
掌握复杂 URL Schemes 你才算初步有了打造适应自己使用情境的自动化流程的能力。iOS 应用的复杂 URL Schemes 就像网站的子页面的链接一样,在首页网址的基础上进行延伸。
具体来看,复杂 URL Schemes 有两种:一种是直接打开某个应用的某个功能,另一种是打开某个功能后直接填写预设的字符。就成为了一个更加实用的 URL Schemes,因为它不光直接让你进入了某个你需要的功能界面,还直接帮你填好了你需要的内容,而跳转后,你需要的只是按一下完成。
有了这样的 URL Schemes,应用之间才可以互相地协作。比如说,当我们在Mr. Reader上看到一篇文章里面写了一个不错的软件的时候,我们可以利用OmniFocus的 URL Schemes 将文章名保存到任务名的部分,把链接保存到备注的部分。在 iOS 8 的 Share Sheet 出现之前,这是唯一在 App 间传输信息的方式。
复杂 URL Schemes 有一个特殊的用例是 Jumpback,字典类 App 用它的很多,比如欧路词典。传统的使用欧陆字典查询单词的 URL Schemes 是:
eudic://dict/想查的单词
在这个基础上,加上一句 Jumpback:
eudic://dict/想查的单词?jumpback=指定URL
就能够做到查完单词以后,按左上角或左下角的返回按钮,回到你想要回到的 App。
并不是每个应用都有它的复杂 URL Schemes,但一般来说,有系统规范的复杂 URL Schemes 的应用都是同类应用中的佼佼者。
x-callback-URL
从一个应用的界面跳转到了另一个应用后,就会在左上角看到回到上一个应用的字样,轻触就能返回到上一个应用。这样的事情我们在打造自己的自动化操作的时候毫无疑问也会想要做到,前面说过的Jumpback是一个选择,除此之外还有更强力的代替者——x-callback-URL,它还有 iOS 9 上「返回上个应用」这一功能不能代替的地方。但是不可否认的是,x-callback-URL 的使用情境比较少,使用难度却又比较高。
我们前面谈到的 URL Schemes 都只有一个目的,不管结果是什么,跳转完成后就会停留在跳转后的应用的界面。但在使用 URL Schemes 的时候,运行结果有时候可能成功,有时候可能失败,有时候我们也会手动将其取消。
如果我们还想让应用根据不同的结果有对应的反应,就要用到 x-callback-URL。比如当上一个 URL Schemes 运行成功以后,我是要回到跳转前的应用?还是要接另一个动作(接上另一段 URL Schemes,打开另一个应用的某个功能)?无论是跳转回上个应用还是打开另一个动作,只要你在运行完一个 URL Schemes 后还想再利用一段新的 URL Schemes 做下一件事,就要靠 x-callback-URL,它的固定语法是:
- 在一个 URL Schemes 后面接&x-success,表示前一个 URL 成功以后下一步做什么;
- 在一个 URL Schemes 后面接&x-error,表示前一个 URL 失败以后下一步做什么;
- 在一个 URL Schemes 后面接&x-cancel,表示取消前一个 URL 的操作结果后下一步做什么;
- 还有一个&x-source 我们遇到了再说。
URL 编码(Encode)
URL 中的字符可以分为两类,一部分可以在链接中正常显示,比如字母、数字还有/等一部分符号。除此之外,全部不能正常显示,需要进行编码才能够作为 URL 的一部分出现。比如空格,在 URL 中就必须表示为%20转换的规则不用深究,网上有很多工具提供 URL 的编码和解码功能,可以把编码过的乱七八糟的 URL 解码为我们看得清爽的字符。这些工具当然也可以反过来把我们常用的字符转换成可以在 URL 中使用的字符。
所以理论上,所有 URL 不支持的字符,都要编码。
自定义 URL Scheme 进行跳转
如果我们希望别人打开我们的 app(名字叫做 SchemeDemo),需要注册自定义 URL Scheme,通过 info.plist –> URL Types –> item0 –> URL Schemes –> 你的TestScheme 来设置,详细步骤如下:
1、点击工程中的 info.plist 文件,当该文件显示在如下窗口时,在列表顶部鼠标选中 Information Property List,选择 +,然后向下滚动弹出的列表并选择 URL types,类型为 NSArray。
![]()
2、点击 URL types 左边剪头打开列表,可以看到 Item 0,一个字典实体。展开 Item 0,可以看到 URL Identifier,一个字符串对象。该字符串是你自定义的 URL scheme 的名字。建议采用反转域名的方法保证该名字的唯一性,比如 com.yourCompany.yourApp。
![]()
3、点击 Item 0 新增一行,从下拉列表中选择 URL Schemes,敲击键盘回车键完成插入。注意 URL Schemes 是一个数组,允许应用定义多个 URL schemes。
![]()
4、展开 URL Schemes 该数据并点击 Item 0。你将在这里定义自定义 URL scheme 的名字。只需要名字,不要在后面追加 ://,比如,如果你输入 iOSDevApp,你的自定义 url 就是 iOSDevApp://。
![]()
此时,整个定义如下图:
![]()
Android URL Scheme
Android中的自定义的URL Scheme是一种页面内跳转协议,也可以被称为URLRouter,就是通过类似打开网页的方式去通过路由打开一个Activity,而非直接通过显式Intent方式去进行跳转。这样隐式intent的方法跳转好处如下:
- 降低耦合性:不需要知道具体要跳转哪个界面,只需要根据需求,按照约定好的URL路由协议发送Intent即可;
- 更为安全:不显示Intent跳转,只要是符合协议的Intent都会有对应的Activity来匹配,避免了跳转到不该出现的页面;
- 更为灵活: 有着更为广泛的应用场景,多种场景中都可以使用URL Scheme
URL Scheme协议格式
上文已经说过,URL Scheme是就通过类似打开网页的方式去通过路由打开一个Activity,其协议格式和我们打开网页输入的网址类似。
一个完整的完整的URL Scheme协议格式由scheme、host、port、path和query组成,其结构如下所示:
<scheme>://<host>:<port>/<path>?<query>
其中scheme既可以是Android中常见的协议,也可以是我们自定义的协议。Android中常见的协议包括content协议、http协议、file协议等,自定义协议可以使用自定义的字符串,当我们启动第三方的应用时候,多是使用自定义协议。
如下是一个自定义协议的URI:xl://goods:8888/goodsDetail?goodsId=10011002
通过上面的路径 Scheme、Host、port、path、query全部包含:
- xl,即为Scheme,代表该Scheme 协议名称
- goods,即为Host,代表Scheme作用于哪个地址域
- 8888,即为port,代表该路径的端口号
- goodsDetail,即为path, 代表Scheme指定的页面
- goodsId,即为query,代表传递的参数
URL Scheme的使用方法
URL Scheme的使用方法简要言之就是先在manifest中配置能接受Scheme方式启动的activity;当需要调用时,将Scheme协议的URi以Data的形式加入到Intent中,隐式调用该activity。
1)在AndroidManifest.xml中对<activity >标签增加<intent-filter>设置Scheme
<activity android:name=".MainActivity"><intent-filter> <!--正常启动--><action android:name="android.intent.action.MAIN"/><category android:name="android.intent.category.LAUNCHER"/></intent-filter><intent-filter> <!--URL Scheme启动--><!--必有项--><action android:name="android.intent.action.VIEW"/><!--如果希望该应用可以通过浏览器的连接启动,则添加该项--><category android:name="android.intent.category.BROWSABLE"/><!--表示该页面可以被隐式调用,必须加上该项--><category android:name="android.intent.category.DEFAULT"/><!--协议部分--><data android:scheme="urlscheme"
android:host="auth_activity"></intent-filter><intent-filter><action android:name="emms.intent.action.check_authorization"/><category android:name="android.intent.category.DEFAULT"/><category android:name="emms.intent.category.authorization"/></intent-filter></activity>上面的设置中可以看到,MainActivity包含多个<intent-filter>设置,第一个是正常的启动,也就是在应用列表中启动;第二个是通过URL Scheme方式启动,其本身也是隐式Intent调用的一种,不同在于添加了<data>属性,定义了其接受URL Scheme协议格式为urlschemel://auth_activity
这里需要说明下,URL Scheme协议格式中,组成URI的这些属性在<data >标签中都是可选的 ,但存在如下的依赖关系:
- 如果没有指定scheme,那么host参数会被忽略
- 如果没有指定host,那么port参数会被忽略
- 如果scheme和host都没有指定,path参数会被忽略
当我们将intent对象中的Uri参数与intent-filter中的<data>标签指定的URI格式进行对比时,我们只对比intent-filter的<data>标签指定的部分,例如:
- 如果intent-filter中只指定了scheme,那么所有带有该sheme的URI都能匹配到该intent-filter。
- 如果intent-filter中只指定了scheme和authority(authority包括host和port两部分)而没有指定path,那么所有具有相同scheme和authority的URI都能匹配到该intent-filter,而不用考虑path为何值。
- 如果intent-filter中同时指定了scheme、authority和path,那么只有具有相同scheme、authority和path的URI才能匹配到该intent-filter。
需要注意的是,intent-filter的<data>标签在指定path的值时,可以在里面使用通配符*,起到部分匹配的效果。
2)使用URL启动Activity
Uri data = Uri.parse("urlschemel://auth_activity");
Intent intent = new Intent(Intent.ACTION_VIEW,data);
//保证新启动的APP有单独的堆栈,如果希望新启动的APP和原有APP使用同一个堆栈则去掉该项
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
try {
startActivityForResult(intent, RESULT_OK);
} catch (Exception e) {
e.printStackTrace();
Toast.makeText(MainActivity.this, "没有匹配的APP,请下载安装",Toast.LENGTH_SHORT).show();
}当然可以在网页中调用:
<a href="urlschemel://auth_activity">打开新的应用</a>
或者是在JS中调用:
window.location = "urlschemel://auth_activity";
3)如何判断URL Scheme是否有效
boolean checkUrlScheme(Intent intent){
PackageManager packageManager = getPackageManager();
List<ResolveInfo> activities = packageManager.queryIntentActivities(intent, 0);
return !activities.isEmpty();
}将子APP在Home Launcher中隐藏
有时候需要把一些辅助性的、较为独立的APP在Home Launcher中隐藏起来,只允许一些特定的APP调用。这个时候,我们可以利用URL Scheme协议来做到这一点,设置AndroidManifest.xml中对<activity >标签如下:
<activity android:name=".MainActivity"><intent-filter><action android:name="android.intent.action.MAIN"/><category android:name="android.intent.category.LAUNCHER"/><category android:name="android.intent.category.BROWSABLE"/><!--表示该页面可以被隐式调用,必须加上该项--><category android:name="android.intent.category.DEFAULT"/><!--协议部分--><data android:scheme="urlscheme"
android:host="auth_activity"></intent-filter></activity>因为Home Launcher列出的应用图标要求必须有Activity同时满足:
<action android:name="android.intent.action.MAIN"/><category android:name="android.intent.category.LAUNCHER"/>
上面的配置中有多余的category和data限制存在,所以并不匹配,不会在Home Launcher出现,但是可以使用URL Scheme来启动。
Uri data = Uri.parse("urlschemel://auth_activity");
Intent intent = new Intent(Intent.ACTION_MAIN,data);
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);这样就可以将一组APP设置一个统一的入口,然后根据实际需要在调用不同子APP,即所谓的APP业务组件化。
URL Scheme的缺点
提示框
我们只能通过固定协议格式的链接来实现跳转,而且打开H5页面时,会出现一个提示框:“是否打开XXX”。用户确认了才会跳转到App中,增加了用户流程。
未安装APP导致的异常
错误处理情况因平台不同,难以统一处理,部分APP会直接跳错误页(比如Android Chrome/41,iOS中老版的Lofter);也有的停留在原页面,但弹出提示“无法打开网页”(比如iOS7);iOS8以及最新的Android Chrome/43 目前都是直接停留在当前页,不会跳出错误提示。
场景支持情况
iOS在实际使用中,腾讯系的微信,QQ明确禁止使用,iOS9以后Safari不再支持通过js,iframe等来触发scheme跳转,并且还加入了确认机制,使得通过js超时机制来自动唤醒APP的方式基本不可用;Android平台则各个app厂商差异很大,比如Chrome从25及以后就同Safari情况一样。
命名冲突或劫持
如果手机中同時存在有两个应用都使用相同的 URL Scheme,那么唤起目标应用时,系统会优先唤起哪一个呢?Apple在后续iOS版本(iOS 11)采用了先到先得原则,如果使用了同一个URL Scheme,只有先安装的app会被启动。然而,攻击者还是可以通过其他方法来利用这个漏洞。
打开方式被禁
微信、QQ等把URL Scheme 打开App这种方式给禁了,但是它们都各自维护着一个白名单,如果Scheme不在该白名单内,那么就不能在他们的App内打开这个App(如果被封锁了那么用户只能通过右上角浏览器内打开App)
iOS Universal Links
Universal Link 是苹果在 WWDC 上提出的 iOS9 的新特性之一。此特性类似于深层链接,并能够方便地通过打开一个 Https 链接来直接启动您的客户端应用(手机有安装 App)。对比起以往所使用的 URL Scheme,这种新特性在实现 web-app 的无缝链接时能够提供极佳的用户体验。
当你的应用支持 Universal Link(通用链接),当用户点击一个链接是可以跳转到你的网站并获得无缝重定向到对应的 APP,且不需要通过 Safari 浏览器。如果你的应用不支持的话,则会在 Safari 中打开该链接。
使用 Universal Link(通用链接)可以让用户在 Safari 浏览器或者其他 APP 的 webview 中拉起相应的 APP,也可以在 APP 中使用相应的功能,从而来把用户引流到 APP 中。这具体是一种怎样的情景呢?举个例子,你的用户 safari 里面浏览一个你们公司的网页,而此时用户手机也同时安装有你们公司的 App;而 Universal Link 能够使得用户在打开某个详情页时直接打开你的 app 并到达 app 中相应的内容页面,从而实施用户想要的操作(例如查看某条新闻,查看某个商品的明细等等)。比如在 Safari 浏览器中进入淘宝网页点击打开 APP 则会使用 Universal Link(通用链接)来拉起淘宝 APP。
Universal link 的特点:
- 唯一性: 不像自定义的 URL Scheme,因为它使用标准的 HTTPS 协议链接到你的 web 站点,所以一般不会被其它的 APP 所声明。另外,URL scheme 因为是自定义的协议,所以在没有安装 app 的情况下是无法直接打开的(在 Safari 中还会出现一个不可打开的弹窗),而 Universal Link(通用链接)本身是一个 HTTPS 链接,所以有更好的兼容性;
- 安全: 当用户的手机上安装了你的 APP,那么系统会去你配置的网站上去下载你上传上去的说明文件(这个说明文件声明了当前该 HTTPS 链接可以打开那些 APP)。因为只有你自己才能上传文件到你网站的根目录,所以你的网站和你的 APP 之间的关联是安全的;
- 可变: 当用户手机上没有安装你的 APP 的时候,Universal Link(通用链接)也能够工作。如果你愿意,在没有安装你的 app 的时候,用户点击链接,会在 safari 中展示你网站的内容;
- 简单: 一个 HTTPS 的链接,可以同时作用于网站和 APP;
- 私有: 其它 APP 可以在不需要知道你的 APP 是否安装了的情况下和你的 APP 相互通信。
Universal Link的优点:
- Custom URL scheme是自定义的协议,因此在没有安装该app的情况下是无法直接打开的。而Universal Links本身也就是一个能够指向一个web页面或者app中的内容页的标准的web link(形如https://example.com) 因此能够很好的兼容其他情况。也就是说,当已经安装了这个app的时候,不需要加载任何web页面,app就会立即启动;当这个app没有安装的时候,就会默认地从当前浏览器中重定向到App Store中引导用户去下载安装这个app。
- Universal links是从服务器上查询是哪个app需要被打开,因此不存在Custom URL scheme那样名字被抢占、冲突的情况。
- Universal links支持从其他app中的UIWebView中跳转到目标app
- 安全性,用universl link去打开的时候,只有你可以通过创建和上传一个允许这个网页去通过这个URL去打开你的app的文件。
- 隐私性,提供Universal link给别的app进行app间的交流,然而对方并不能够用这个方法去检测你的app是否被安装。
Universal link 配置和运行
1) 配置 App ID 支持 Associated Domains
登录https://developer.apple.com/ 苹果开发者中心,找到对应的 App ID,在 Application Services 列表里有 Associated Domains 一条,把它变为 Enabled 就可以了。
2 )配置 iOS App 工程
Xcode 11.0 版本:工程配置中相应功能:targets->Signing&Capabilites->Capability->Associated Domains,在其中的 Domains 中填入你想支持的域名,也必须必须以 applinks:为前缀。
Xcode 11.0 以下版本:工程配置中相应功能:targets->Capabilites->Associated Domains,在其中的 Domains 中填入你想支持的域名,必须以 applinks:为前缀。
3) 配置和上传 apple-app-association
究竟哪些的 url 会被识别为 Universal Link,全看这个 apple-app-association 文件 Apple Document UniversalLinks.html
- 你的域名必须支持 Https
- 域名根目录或者.well-known目录下放这个文件apple-app-association,不带任何后缀。
- 文件为 json 保存为文本即可
- json 按着官网要求填写即可
apple-app-site-association模板:
{"applinks": {"apps": [],"details": [
{"appID": "9JA89QQLNQ.com.apple.wwdc","paths": [ "/wwdc/news/", "/videos/wwdc/2015/*"]
},
{"appID": "ABCD1234.com.apple.wwdc","paths": [ "*" ]
}
]
}
}说明:
- appID:组成方式是yourapp’s bundle identifier。如上面的 9JA89QQLNQ 就是 teamId。登陆开发者中心,在 Account -> Membership 里面可以找到 Team ID。
- paths:设定你的 app 支持的路径列表,只有这些指定的路径的链接,才能被 app 所处理。星号的写法代表了可识 别域名下所有链接。
上传指定文件:上传该文件到你的域名所对应的根目录或者.well-known 目录下,这是为了苹果能获取到你上传的文件。上传完后,自己先访问一下,看看是否能够获取到,当你在浏览器中输入这个文件链接后,应该是直接下载 apple-app-site-association 文件。
验证 Universal link 生效
可以使用 iOS 自带的备忘录程序,输入链接,长按链接,如果弹出菜单中有”在‘xxx’中打开”,即表示配置生效。或者将要测试的网址在Safari中打开,在出现的网页上方下滑,可以看到有在”xxx”应用中打开, 出现菜单。
![]()
当点击某个链接,直接可以进我们的 app 了,但是我们的目的是要能够获取到用户进来的链接,根据链接来展示给用户相应的内容。
在AppDelegate里中实现代理方法,官方链接: Handling Universal Links
Objective-C:
- (BOOL)application:(UIApplication *)application continueUserActivity:(NSUserActivity *)userActivity restorationHandler:(void (^)(NSArray * _Nullable))restorationHandler {
if ([userActivity.activityType isEqualToString:NSUserActivityTypeBrowsingWeb])
{
NSURL *url = userActivity.webpageURL;
if (url是我们希望处理的)
{
//进行我们的处理
}
else
{
[[UIApplication sharedApplication] openURL:url];
}
}
return YES;
}
Swift:
func application(_ application: UIApplication,
continue userActivity: NSUserActivity,
restorationHandler: @escaping ([Any]?) -> Void) -> Bool
{
guard userActivity.activityType == NSUserActivityTypeBrowsingWeb,
let incomingURL = userActivity.webpageURL,
let components = NSURLComponents(url: incomingURL, resolvingAgainstBaseURL: true),
let path = components.path,
let params = components.queryItems else {
return false
}
print("path = \(path)")
if let albumName = params.first(where: { $0.name == "albumname" } )?.value,
let photoIndex = params.first(where: { $0.name == "index" })?.value {
print("album = \(albumName)")
print("photoIndex = \(photoIndex)")
return true
} else {
print("Either album name or photo index missing")
return false
}
}Universal link跨域问题
Universal Link有跨域问题,Universal Link必须要求跨域,如果不跨域,就不会跳转(iOS 9.2之后的改动)要求具备跨域能力即可, 假如当前网页的域名是A,当前网页发起跳转的域名是B,必须要求B和A是不同域名才会触发Universal Link,如果B和A是相同域名,只会继续在当前WebView里面进行跳转,哪怕你的Universal Link一切正常,根本不会打开App 2. Universal Link请求apple-app-site-association时机
- 当我们的App在设备上第一次运行时,如果支持Associated Domains功能,那么iOS会自动去GET定义的Domain下的apple-app-site-association文件
- iOS会先请求https://domain.com/.well-known/apple-app-site-association,如果此文件请求不到,再去请求https://domain.com/apple-app-site-association,所以如果想要避免服务器接收过多GET请求,可以直接把apple-app-site-association放在./well-known目录下
Universal Link更新
apple-app-association的更新时机有以下两种:
- 每次App安装后的第一次Launch,会拉取apple-app-association
- Appstore每次App的版本更新后的第一次Launch,也会更新apple-app-association
所以反复重新杀APP重开完全没用,删了App重装确实有用,但不可能让用户这么去做。也就是说,一旦不小心因为意外apple-app-association,想要挽回又让那部分用户无感,App再发一个版本就好了。
Universal Link用户行为
Universal Link 触发后打开App,这时候App的状态栏右上角会有文字提示来自XXApp,可以点状态栏的文字快速返回原来的AP
如果用户点了返回微信,就会被苹果记住,认为用户并不需要跳出原App打开新App,因此这个App的Universal Link会被关闭,再也无效。
想要开启也不是不行,让用户重新用safari打开,universal link的页面,然后会出现很像苹果smart bar的东西,那个东西点了后就能打开
H5 端的 Universal Link 业务部署
H5 端的 Universal Link 跳转,从产品经理的角度看,需要满足以下 2 个需求:
- 如果已安装 App,跳转对应界面
- 如果没安装 App,跳转 App 下载界面
H5 端部署 Universal Link 示例:
router.use('/view', function (req, res, next) {
var path = req.path;
res.redirect('https://www.xxx.com/view' + path + '?xxx=xxx');
});整个效果就是
- 跳转https://www.xxx.com/view/*
- 已安装 App
- 打开 App 触发 handleUniversalLink
- 走到/view/分支,拼接阅读页路由跳转
- 未安装 AppWebView
- 原地跳转https://www.xxx.com/view/*
- 命中服务器的重定向逻辑
- 重定向到https://www.xxx.com/view/*
- 打开相应的 H5 页面
Chrome Intent
在很多应用中需要我们从浏览器中直接启动应用,大多数采用的是上面提到的第一种scheme的方式,问题是如果手机中没有应用,该url会跳转到一个错误的界面。
Google官方在chrome中推出了一种Android Intents的方式来实现应用启动,通过在iframe中设置src为:
- intent:HOST/URI-path // Optional host
- #Intent;
- package=[string];
- action=[string];
- category=[string];
- component=[string];
- scheme=[string];
- end;
mainfest文件中定义要启动的activity:
<activity
android:name=".ui.activity.SplashActivity"
android:exported="true"
android:screenOrientation="portrait"
android:theme="@style/NormalSplash"><intent-filter><action android:name="android.intent.action.MAIN" /><category android:name="android.intent.category.LAUNCHER" /></intent-filter><intent-filter><action android:name="android.intent.action.VIEW" /><category android:name="android.intent.category.DEFAULT" /><category android:name="android.intent.category.BROWSABLE" /><data
android:host="app.puxinwangxiao.com"
android:scheme="pxwxstudent" /></intent-filter></activity>定义一个a标签为
<a href="intent://app.domain.com/#Intent;scheme=xyz;package=com.xxx.xxx;end">open Android App</a>
在浏览器中点击a标签,就可以启动应用程序的对应activity了。如果手机中没有相应的应用,防止跳转到错误页面,将a标签设置为:
<a href="intent://app.domain.com/#Intent;scheme= xyz;package=com.xxx.xxx;S.browser_fallback_url=https://www.domain.com;end">open Android App</a>
这样如果没有对应应用,该链接就会跳转到==S.browser_fallback_url==指定的url上。
备注:很多第三方浏览器会拦截掉chrome intent启动应用的请求。
Android App Link
类似 Universal Links, Android App Link采取类似的机制:使用标准的 Web 页面 URL,同时绑定对应的 App。在 Android >= 6 的系统中支持这一机制。
Android App Links有以下几点好处:
- 安全性/特殊性:由于Android App Links使用了HTTP/HTTPS URL的方式向开发者的服务器进行连接认证,所以其他应用无法使用我们的链接
- 无缝的用户体验:当用户未安装我们的应用时,由于使用的是HTTP/HTTPS URL,会直接打开一个网页,我们可以在这个网页中展示应用介绍等,而不是显示404或者是其他错误页面
- 支持Instant Apps:可以使用App Links直接打开一个未安装的Instant App
- 支持Google Search或其他浏览器:用户可以直接在Google Search/Google Assistant/手机浏览器/屏幕搜索中直接通过点击一个URL来打开我们的指定页面
要添加Android App Links到应用中,需要在应用里定义通过Http(s)地址打开应用的intent filter,并验证你确实拥有该应用和该网站。如果系统成功验证到你拥有该网站,那么系统会直接把URL对应的intent路由到你的应用。
为了验证你对应用和网站的所有权,以下两个步骤是必须的:
- 在AndroidManifest里要求系统自动进行App Links的所有权验证。这个配置会告诉Android系统去验证你的应用是否属于在intent filter内指定的URL域名。
- 在以下链接地址里,放置一个数字资产链接的Json文件,声明你的网址和应用之间的关系:https://domain.name/.well-known/assetlinks.json
在app中激活App links
告诉安卓系统去验证app与域名之间的关系。因为我们已经在app中注册了该域名,就不会再出现弹框。找到AndroidManifest.xml文件,在处理深度链接路由的activity(第三步将讲解如何创建这样的Activity)中添加android:autoVerify=”true”到intent-filter:
<activity
android:name=".ParseDeepLinkActivity"
android:alwaysRetainTaskState="true"
android:launchMode="singleTask"
android:noHistory="true"
android:theme="@android:style/Theme.Translucent.NoTitleBar"><intent-filter android:autoVerify="true"><data android:scheme="http" android:host="yourdomain.com" /><data android:scheme="https" android:host="yourdomain.com" /><action android:name="android.intent.action.VIEW" /><category android:name="android.intent.category.DEFAULT" /><category android:name="android.intent.category.BROWSABLE" /></intent-filter></activity>
这个配置告诉安卓去验证一个文件,这个文件地址是https://yourdomain.com/.well-known/statements.json。如果存在这个文件,同时验证成功,那么用户点击该域名之下的链接时,就可以直接到app,弹出框就可以避免。否则app就没有成为默认选项,弹出框就会呈现给用户。
上传web-app关联文件(statements.json)
基于安全的原因,这个文件必须通过SSL的GET请求获得。
[{"relation": ["delegate_permission/common.handle_all_urls"],"target": {"namespace": "android_app","package_name": "com.mycompany.myapp","sha256_cert_fingerprints": ["6C:EC:C5:0E:34:AE....EB:0C:9B"]
}
}]可以在AndroidManifest.xml 文件中找到app的package name。还需要通过在终端中执行ava keytool 产生一个sha256指纹:
keytool -list -v -keystore /path/to/app/release-key.keystore
你需要向keystore添加持有app release keys的 app路径。这个路径依赖于项目设置,因此不同的app是不同的。可以在谷歌的文档中找到更多关于如何找到keystore的信息。
最后,上传这个文件到服务器的/.well-known/statements.json。为了避免今后每个app链接请求都访问网络,安卓只会在app安装的时候检查这个文件。如果你能在请求https://yourdomain.com/.well-known/statements.json 的时候看到这个文件(替换成自己的域名哈),那么可以继续下一步了。
注:目前可以通过http获得这个文件,但是在M最终版里则只能通过HTTPS验证。确保你的web站点支持HTTPS请求。
在app中处理applink
public class ParseDeepLinkActivity extends Activity {
public static final String PRODUCTS_DEEP_LINK = "/products";
public static final String XMAS_DEEP_LINK = "/campaigns/xmas";
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
// Extrapolates the deeplink data
Intent intent = getIntent();
Uri deeplink = intent.getData();
// Parse the deeplink and take the adequate action
if (deeplink != null) {
parseDeepLink(deeplink);
}
}
private void parseDeepLink(Uri deeplink) {
// The path of the deep link, e.g. '/products/123?coupon=save90'
String path = deeplink.getPath();
if (path.startsWith(PRODUCTS_DEEP_LINK)) {
// Handles a product deep link
Intent intent = new Intent(this, ProductActivity.class);
intent.putExtra("id", deeplink.getLastPathSegment()); // 123
intent.putExtra("coupon", deeplink.getQueryParameter("coupon")); // save90
startActivity(intent);
} else if (XMAS_DEEP_LINK.equals(path)) {
// Handles a special xmas deep link
startActivity(new Intent(this, XmasCampaign.class));
} else {
// Fall back to the main activity
startActivity(new Intent(context, MainActivity.class));
}
}
}深度链接 Deeplink
深度链接是指当用户打开移动应用时向其提供个性化的内容,或将用户带到应用内特定位置的操作。通过这种操作,您可以为用户提供优质的用户体验,从而极大加强用户与应用的互动。
- 在浏览器或者短信中打开App,如果安装了就能直接打开App,否则引导下载。对于Android而言,这里主要牵扯的技术就是deeplink,也可以简单看成scheme。
- 其实,AppLink就是特殊的Deeplink,只不过它多了一种类似于验证机制,如果验证通过,就设置默认打开,如果验证不过,则退化为deeplink,如果单从APP端来看,区别主要在Manifest文件中的android:autoVerify=”true”。
- 还有在微信中,也可以作出这样操作。如果用户已经安装App,点击跳转App则会通过应用宝打开该应用并且跳转到相应的页面,这种也是一种AppLink。
总结来说,Deeplink,又叫深度链接技术,是指在App/短信/广告里点击链接,能直接跳转到目标App具体位置的技术,深度链接打破了网站与App间的壁垒,成为实现网站与App相互跳转的桥梁。开发者不仅可以通过deeplink实现网站到App互相跳转,也可以实现从多个平台(QQ、微信、微博、Twitter、Facebook、短信、各大浏览器等)到App内指定页的跳转。例如用户将电商App内的一个详情页链接通过短信形式发送给其他亲友,用户点击短信内的链接就能打开对应的H5页面,然后直接跳转到电商App内的指定详情页,而不是App首页。如果用户并未安装App,那么就会跳转到App下载页面。等用户安装打开App后仍然能跳转到指定页面。Deeplink技术不仅可以实现场景快速还原,缩短用户使用路径,更重要的是能够用于App拉新推广场景,降低用户流失率。
Deep Linking只是一个概念, 是指通过一个链接进入另一个网站/App,并直接浏览其内部的某个页面。 Deep Linking 给用户带来的是非常顺滑的浏览体验,尤其在 Web 世界中 Deep Linking 的实现非常容易。
但如果要进入 App 并定位到对应的页面则较为困难,URI Scheme, Universal Links, Android App Links, 以及 Chrome Intent 都是为了解决从 Web 页面 Deep Linking 到 App 而做的尝试。
每种实现方式都有其适用的平台和浏览器,要兼容多数浏览器需要根据 User Agent 应用不同的策略。 这些实现方式的行为也不一致,可能需要配合产品需求才能确定结合哪几种实现方式。 这些实现在下文有详细的介绍,下表中先大概列举各种实现的区别:
| 技术 | Universal Link | Android App Link | URI Scheme | Chrome Intent |
| 平台要求 | >= iOS 9 | >= Android 6 | Chrome 1 < 25, iOS | Chrome 1 >= 25 |
| 未安装表现 | 打开 Web 页面 | 打开 Web 页面 | 发生错误 | 可以打开 Web 页面 |
| 能否不发生跳转 | 不能 | 不能 | 能 | 能 |
| 能否去下载页面 | 能 | 能 | 不能 | 能 |
| iframe 触发 | 不支持 | 不支持 | Chrome 1 <= 18, iOS < 9 | 不支持 |
| 链接格式 2 | 正常的 URL | 正常的 URL | 自定义协议的 URL | intent 协议的 URL |
JavaScript 获取成功与否
上述所有调起方式都必须通过页面请求(除了特定情况下的 iframe), 没有 JavaScript API 可用。理论上不存在调起结果回调。
但实践上可以通过 setTimeout 来检查页面是否还在运行,以及页面是否中断过。 原理是如果页面切走(这意味着成功调起),setTimeout 回调的触发时间点会延迟。 这一方式不够准确,但只有这一种办法。
- 如果被判定为调起成功,则一定是调起成功的。
- 如果被判定为调起失败,则有可能调起成功。
即存在很大概率的 False Negative,但不存在 False Positive。
关于国产浏览器
这一部分讨论这三个浏览器的表现:UC, 微信,QQ。它们占据了系统浏览器之外的大多数市场份额,表现也惊人地一致。
- Android 下它们会拦截掉所有页面调起。需要提示用户从系统浏览器中打开。
- iOS 下它们会拦截 URI Scheme,既不会弹框也不会调起。对于 Universal Link 会直接打开 Web 页面而不调起。
其中 UC 浏览器在 iOS < 9 的环境下尝试 URI Scheme 调起很可能会直接崩溃。 由于浏览器兼容性问题,以及 App 安装率不可能是 100%,调起成功率一般会很低尤其在 Android 下。
延迟深度链接(Deferred Deep Linking)
相比deeplink,它增加了判断APP是否被安装,用户匹配的2个功能;
- 当用户点击链接的时候判断APP是否安装,如果用户没有安装时,引导用户跳转到应用商店下载应用。
- 用户匹配功能,当用户点击链接时和用户启动APP时,分别将这两次用户Device Fingerprint(设备指纹信息)传到服务器进行模糊匹配,使用户下载且启动APP时,直接打开相应的指定页面。
通过上面的2个技术方案,不仅:
- 可以让被分享者更快更便捷的回到APP,且回到指定的活动页面,而且:
- 可以引导未安装APP的用户下载APP、
- 分享者和被分享者的关系链会通过设备指纹信息记录下来,在业务场景中给出相应的奖励。
Deferred Deeplink可以先判断用户是否已经安装了App应用,如果没有则先引导至App应用商店中下载App, 在用户安装App后跳转到指定App页面Deeplink中。
![]()
除了上述Deeplink中的运营有点外,Deferred Deeplink在未安装App应用人群定向推广中效果更佳突出。另外国外的App运营在社交推广中广泛使用Deferred Deeplink技术,比如一个购物App中用户分享了一个自己喜欢的产品到社交账户中,如果没有使用Deferred Deeplink。其好友看到分享,点击下载安装打开App应用后,很可能找不到其好友分享的产品,导致较高的用户流失率。
Deferred DeepLink的实现思路
任何匹配的问题都可以转化到获取唯一标示的问题。很容易联想到http里面的session和cookies。由于手机系统的沙盒模式,阻断了App之间的数据共享。也就是说App的cookies跟手机浏览器的cookies是分开的,无法互通。
解决方案一:通过设备唯一ID
如Android的OIAD,iOS的idfv。此方案仅适合一个APP往另外一个APP引流的场景。
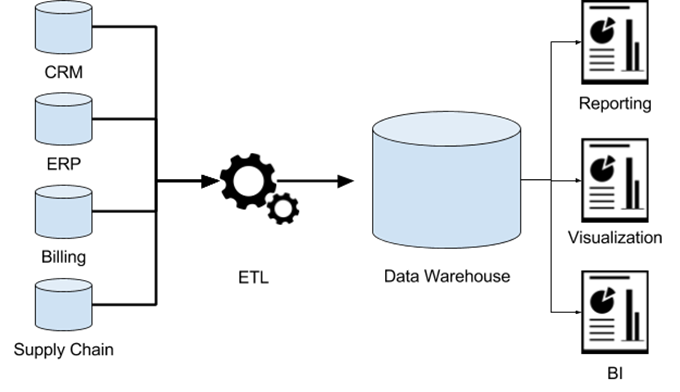
解决方案二:通过IP地址+设备信息(设备尺寸、操作系统等)+时间限定(比如10分钟)
![]()
解决方案三:剪切板方案
H5页面在点击下载时自动调用剪切板复制当前用户渠道ID( 口令码方案),APP每次启动时调用剪切板内容格式符合则认定该用户和H5用户为同一用户。
第三方库
支持deep linking 和 deferred deep linking 的第三方服务,比如 AppsFlyer和 Branch。涉及内容较多,这里就先不做展开。后面会单独进行深入分析。